DeployContract transaction crashed during the final “code distribution” step, though the finished chunk still propagated. The Near One team released a hot‑fix that simply truncated the recipient list, which worked for any nodes that upgraded to adopt the fix, but the fix didn’t account for the creation of a Reed-Solomon encoder on un-upgraded nodes, which caused any un‑upgraded node to crash when it tried to forward those contract parts, temporarily enlarging the blast radius; block throughput dipped to ~0.1 blocks/s for about half an hour and then recovered as most validators adopted the patch.
Timeline and Details
July 3rd, 2:30 AM, UTC
First report of a validator node crashing.
July 3rd, 2:48 AM, UTC
Second report, the same node has crashed again.
July 3rd, 2:54 AM, UTC
Initial assessment confirming the number of parts has to be over 256. At this point the chain is progressing and chunks are produced fine, some nodes occasionally crash and restart. Contract deployment is not a frequent action, thus the impact is limited.
July 3rd, 08:11 AM, UTC
A domain expert reviews the issue and identifies the root cause.
July 3rd, 08:27 AM, UTC
A quick fix is ready and sent for review. The fix disables contract code distribution if the number of recipients is over 256.
July 3rd, 10:08 AM, UTC
A concern is raised that not sending the contract code to the validators may create performance issues as they would need to fetch the contract code during state witness validation, slowing down this step. Considering the frequency of contract deployment the performance impact was overestimated.
July 3rd, 10:35 AM, UTC
Another fix is ready, truncating the list of recipients if it is longer than 256. This fix would prevent the chunk producer from crashing. The team does not realize that the recipients would be crashing instead if they are not applying the same fix.
July 3rd, 3:41 PM, UTC
After merging and testing the fix, the 2.6.5 release is ready.
July 3rd, 5:44 PM, UTC
2.6.5 is published and announced as CODE_YELLOW_MAINNET.
July 4th, 11:30 PM, UTC
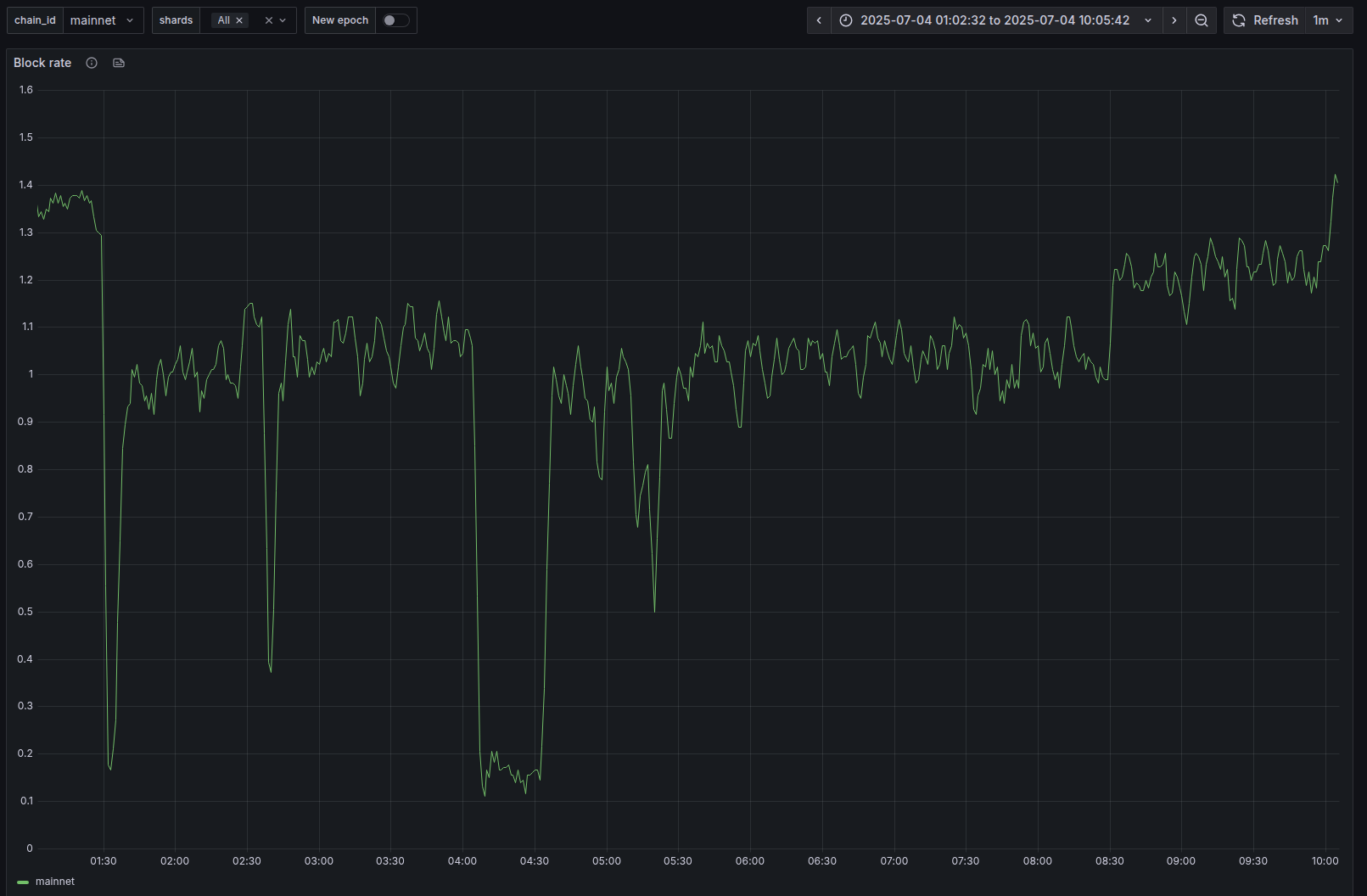
As the validators adopt the version 2.6.5 they no longer crash upon contract deployment. Unfortunately, non-upgraded receiving validators start crashing. The Mainnet block rate drops to 0.15 (1 block in 7 seconds), the network performance degrades.
July 4th, 7:17 AM, UTC
2.6.5 is adopted by 73% of the validators, the block rate is back to normal. During the incident the block rate went down to almost 0.1 for 30 minutes (1 block in 10 seconds).
Conclusion
The original issue did not cause significant impact and was correctly assessed as CODE_YELLOW. Unfortunately we have overestimated potential performance impact of a simple fix and opted for a more complex one trying to preserve the optimized behavior, which caused a network degradation. At this point we should have upgraded to CODE_RED to accelerate the adoption of the patch.
NEAR One’s release testing includes a gradual rollout of a new version and could have caught the issue, but the full suite takes days to run and does not have hundreds of validators.
Going forward we will be taking a more careful approach towards mainnet hotfixes, opting for the safest option possible and making sure the changes are properly tested. That being said, dealing with Mainnet incidents is extremely hard due to the time pressure and severity of potential consequences.
Finally, we would like to highlight that this issue has been triggered due to progressing decentralization of NEAR and growing number of participating validators.
]]>